Caddy 效能分析
程式效能分析 (program profile) 是程式在運行時資源使用情況的快照。效能分析對於識別問題區域、排除錯誤和崩潰以及優化程式碼非常有幫助。
Caddy 使用 Go 的工具來捕獲效能分析,稱為 pprof,它內建於 go 命令中。
效能分析報告 CPU 和記憶體的消耗者,顯示 goroutine 的堆疊追蹤,並幫助追蹤死鎖或高爭用同步原語。
在回報 Caddy 中的某些錯誤時,我們可能會要求提供效能分析。本文可以提供幫助。它描述了如何使用 Caddy 取得效能分析,以及如何使用和解釋一般的 pprof 效能分析結果。
開始之前需要了解的兩件事
- Caddy 效能分析不涉及安全性敏感資訊。 它們包含良性的技術讀數,而不是記憶體的內容。它們不會授予系統的存取權。它們可以安全地共享。
- 效能分析是輕量級的,可以在生產環境中收集。 事實上,對於許多使用者來說,這是一個推薦的最佳實踐;請參閱本文後續章節。
取得效能分析
效能分析可透過 管理介面 在 /debug/pprof/ 取得。在運行 Caddy 的機器上,在瀏覽器中打開它
https://127.0.0.1:2019/debug/pprof/
您會注意到一個簡單的計數和連結表格,例如
| 計數 | 效能分析 |
|---|---|
| 79 | allocs |
| 0 | block |
| 0 | cmdline |
| 22 | goroutine |
| 79 | heap |
| 0 | mutex |
| 0 | profile |
| 29 | threadcreate |
| 0 | trace |
| 完整 goroutine 堆疊傾印 |
這些計數是快速識別洩漏的便捷方法。如果您懷疑有洩漏,請重複刷新頁面,您會看到其中一個或多個計數不斷增加。如果 heap 計數增長,則可能是記憶體洩漏;如果 goroutine 計數增長,則可能是 goroutine 洩漏。
點擊瀏覽這些效能分析,看看它們是什麼樣子。有些可能是空的,這在大多數時候是正常的。最常用的包括 goroutine(函數堆疊)、heap(記憶體)和 profile(CPU)。其他效能分析對於排除互斥鎖爭用或死鎖很有用。
在底部,有每個效能分析的簡單描述
- allocs: 所有過去記憶體分配的抽樣
- block: 導致在同步原語上阻塞的堆疊追蹤
- cmdline: 當前程式的命令列調用
- goroutine: 所有當前 goroutine 的堆疊追蹤。使用 debug=2 作為查詢參數,以與未恢復的 panic 相同的格式匯出。
- heap: 活動物件的記憶體分配抽樣。您可以指定 gc GET 參數以在取得 heap 樣本之前運行 GC。
- mutex: 爭用互斥鎖持有者的堆疊追蹤
- profile: CPU 效能分析。您可以以秒為單位指定 duration GET 參數。取得效能分析檔案後,使用 go tool pprof 命令來調查效能分析。
- threadcreate: 導致建立新 OS 執行緒的堆疊追蹤
- trace: 當前程式的執行追蹤。您可以以秒為單位指定 duration GET 參數。取得追蹤檔案後,使用 go tool trace 命令來調查追蹤。
下載效能分析
點擊上面 pprof 索引頁面上的連結將為您提供文字格式的效能分析。這對於偵錯很有用,這也是 Caddy 團隊偏好的方式,因為我們可以掃描它以尋找明顯的線索,而無需額外的工具。
但二進制實際上是預設格式。HTML 連結會附加 ?debug= 查詢字串參數以將它們格式化為文字,除了 (CPU) “profile” 連結,它沒有文字表示形式。
這些是您可以設定的查詢字串參數(來自 Go 文件)
debug=N(除了 cpu 之外的所有效能分析): 回應格式:N = 0:二進制 (預設),N > 0:純文字gc=N(heap 效能分析): N > 0:在效能分析之前運行垃圾回收週期seconds=N(allocs、block、goroutine、heap、mutex、threadcreate 效能分析): 返回 delta 效能分析seconds=N(cpu、trace 效能分析): 給定持續時間的效能分析
由於這些是 HTTP 端點,您也可以使用任何 HTTP 客戶端(如 curl 或 wget)來下載效能分析。
下載效能分析後,您可以將它們上傳到 GitHub issue 回覆中,或使用像 pprof.me 這樣的網站。對於 CPU 效能分析,flamegraph.com 是另一個選擇。
遠端存取
如果您已經能夠在本機存取管理 API,請跳過本節。
預設情況下,Caddy 的管理 API 僅可透過 loopback socket 存取。但是,至少有 3 種方法可以遠端存取 Caddy 的 /debug/pprof 端點
透過您的站點進行反向代理
一個簡單的選擇是直接從您的站點進行反向代理
reverse_proxy /debug/pprof/* localhost:2019 {
header_up Host {upstream_hostport}
}
當然,這會使可以連接到您站點的人員可以使用效能分析。如果這不是您所期望的,您可以使用您選擇的 HTTP auth 模組添加一些身份驗證。
(不要忘記 /debug/pprof/* 匹配器,否則您將代理整個管理 API!)
SSH 通道
另一種方法是使用 SSH 通道。這是使用 SSH 協定在您的電腦和伺服器之間建立的加密連線。在您的電腦上運行類似這樣的命令
ssh -N username@example.com -L 8123:localhost:2019這會將 localhost:8123(在您的本機電腦上)隧道傳輸到 example.com 上的 localhost:2019。請務必根據需要替換 username、example.com 和端口。
然後在另一個終端機中,您可以像這樣運行 curl
curl -v https://127.0.0.1:8123/debug/pprof/ -H "Host: localhost:2019"您可以通過在通道的兩側都使用端口 2019 來避免需要 -H "Host: ..."(但這需要端口 2019 尚未在您自己的電腦上被佔用,即沒有在本機運行 Caddy)。
在通道處於活動狀態時,您可以存取任何和所有的管理 API。在 ssh 命令上輸入 Ctrl+C 以關閉通道。
長時間運行的通道
使用上述命令運行通道需要您保持終端機打開。如果您想在後台運行通道,您可以像這樣啟動通道
ssh -f -N -M -S /tmp/caddy-tunnel.sock username@example.com -L 8123:localhost:2019這將在後台啟動並在 /tmp/caddy-tunnel.sock 建立一個控制 socket。然後,您可以使用控制 socket 在完成後關閉通道
ssh -S /tmp/caddy-tunnel.sock -O exit e遠端管理 API
您還可以配置管理 API 以接受授權客戶端的遠端連線。
(TODO:撰寫關於此主題的文章。)
Goroutine 效能分析
goroutine 傾印對於了解存在哪些 goroutine 以及它們的調用堆疊很有用。換句話說,它讓我們了解當前正在執行或正在阻塞/等待的程式碼。
如果您點擊 “goroutines” 或前往 /debug/pprof/goroutine?debug=1,您會看到 goroutine 列表及其調用堆疊。例如
goroutine profile: total 88
23 @ 0x43e50e 0x436d37 0x46bda5 0x4e1327 0x4e261a 0x4e2608 0x545a65 0x5590c5 0x6b2e9b 0x50ddb8 0x6b307e 0x6b0650 0x6b6918 0x6b6921 0x4b8570 0xb11a05 0xb119d4 0xb12145 0xb1d087 0x4719c1
# 0x46bda4 internal/poll.runtime_pollWait+0x84 runtime/netpoll.go:343
# 0x4e1326 internal/poll.(*pollDesc).wait+0x26 internal/poll/fd_poll_runtime.go:84
# 0x4e2619 internal/poll.(*pollDesc).waitRead+0x279 internal/poll/fd_poll_runtime.go:89
# 0x4e2607 internal/poll.(*FD).Read+0x267 internal/poll/fd_unix.go:164
# 0x545a64 net.(*netFD).Read+0x24 net/fd_posix.go:55
# 0x5590c4 net.(*conn).Read+0x44 net/net.go:179
# 0x6b2e9a crypto/tls.(*atLeastReader).Read+0x3a crypto/tls/conn.go:805
# 0x50ddb7 bytes.(*Buffer).ReadFrom+0x97 bytes/buffer.go:211
# 0x6b307d crypto/tls.(*Conn).readFromUntil+0xdd crypto/tls/conn.go:827
# 0x6b064f crypto/tls.(*Conn).readRecordOrCCS+0x24f crypto/tls/conn.go:625
# 0x6b6917 crypto/tls.(*Conn).readRecord+0x157 crypto/tls/conn.go:587
# 0x6b6920 crypto/tls.(*Conn).Read+0x160 crypto/tls/conn.go:1369
# 0x4b856f io.ReadAtLeast+0x8f io/io.go:335
# 0xb11a04 io.ReadFull+0x64 io/io.go:354
# 0xb119d3 golang.org/x/net/http2.readFrameHeader+0x33 golang.org/x/net@v0.14.0/http2/frame.go:237
# 0xb12144 golang.org/x/net/http2.(*Framer).ReadFrame+0x84 golang.org/x/net@v0.14.0/http2/frame.go:498
# 0xb1d086 golang.org/x/net/http2.(*serverConn).readFrames+0x86 golang.org/x/net@v0.14.0/http2/server.go:818
1 @ 0x43e50e 0x44e286 0xafeeb3 0xb0af86 0x5c29fc 0x5c3225 0xb0365b 0xb03650 0x15cb6af 0x43e09b 0x4719c1
# 0xafeeb2 github.com/caddyserver/caddy/v2/cmd.cmdRun+0xcd2 github.com/caddyserver/caddy/v2@v2.7.4/cmd/commandfuncs.go:277
# 0xb0af85 github.com/caddyserver/caddy/v2/cmd.init.1.func2.WrapCommandFuncForCobra.func1+0x25 github.com/caddyserver/caddy/v2@v2.7.4/cmd/cobra.go:126
# 0x5c29fb github.com/spf13/cobra.(*Command).execute+0x87b github.com/spf13/cobra@v1.7.0/command.go:940
# 0x5c3224 github.com/spf13/cobra.(*Command).ExecuteC+0x3a4 github.com/spf13/cobra@v1.7.0/command.go:1068
# 0xb0365a github.com/spf13/cobra.(*Command).Execute+0x5a github.com/spf13/cobra@v1.7.0/command.go:992
# 0xb0364f github.com/caddyserver/caddy/v2/cmd.Main+0x4f github.com/caddyserver/caddy/v2@v2.7.4/cmd/main.go:65
# 0x15cb6ae main.main+0xe caddy/main.go:11
# 0x43e09a runtime.main+0x2ba runtime/proc.go:267
1 @ 0x43e50e 0x44e9c5 0x8ec085 0x4719c1
# 0x8ec084 github.com/caddyserver/certmagic.(*Cache).maintainAssets+0x304 github.com/caddyserver/certmagic@v0.19.2/maintain.go:67
...
第一行,goroutine profile: total 88,告訴我們正在查看的內容以及有多少 goroutine。
goroutine 列表如下。它們按其調用堆疊依頻率降序排列。
goroutine 行具有以下語法:<count> @ <addresses...>
該行以具有關聯調用堆疊的 goroutine 計數開始。@ 符號表示調用指令地址(即,啟動 goroutine 的函數指標)的開始。每個指標都是函數調用或調用幀。
您可能會注意到,您的許多 goroutine 共享相同的第一個調用地址。這是您程式的 main 函數或入口點。有些 goroutine 不會從那裡開始,因為程式有各種 init() 函數,並且 Go 運行時也可能產生 goroutine。
以下各行以 # 開頭,實際上只是為了讀者方便而添加的註解。它們包含 goroutine 的當前堆疊追蹤。頂部表示堆疊的頂部,即當前正在執行的程式碼行。底部表示堆疊的底部,或 goroutine 最初開始運行的程式碼。
堆疊追蹤具有以下格式
<address> <package/func>+<offset> <filename>:<line>
地址是函數指標,然後您將看到 Go 套件和函數名稱(如果它是方法,則帶有關聯的類型名稱),以及函數內的指令偏移量。然後,也許是最有用的資訊,檔案和行號在末尾。
完整 goroutine 堆疊傾印
如果我們將查詢字串參數更改為 ?debug=2,我們將獲得完整傾印。這包括每個 goroutine 的詳細堆疊追蹤,並且相同的 goroutine 不會被折疊。在繁忙的伺服器上,此輸出可能非常大,但它是有趣的資訊!
讓我們看一下與上面第一個調用堆疊對應的一個(已截斷)
goroutine 61961905 [IO wait, 1 minutes]:
internal/poll.runtime_pollWait(0x7f9a9a059eb0, 0x72)
runtime/netpoll.go:343 +0x85
...
golang.org/x/net/http2.(*serverConn).readFrames(0xc001756f00)
golang.org/x/net@v0.14.0/http2/server.go:818 +0x87
created by golang.org/x/net/http2.(*serverConn).serve in goroutine 61961902
golang.org/x/net@v0.14.0/http2/server.go:930 +0x56a
儘管它很冗長,但此傾印唯一提供的最有用的資訊是每個 goroutine 的第一行和最後一行。
第一行包含 goroutine 的編號 (61961905)、狀態 (“IO wait”) 和持續時間 (“1 minutes”)
-
Goroutine 編號: 是的,goroutine 有編號!但它們不會暴露給我們的程式碼。但是,這些編號在堆疊追蹤中特別有用,因為我們可以看到哪個 goroutine 產生了這個 goroutine(請參見結尾:“created by ... in goroutine 61961902”)。下面顯示的工具可以幫助我們繪製此視覺圖形。
-
狀態: 這告訴我們 goroutine 當前正在做什麼。以下是一些您可能會看到的可能狀態
running:執行程式碼 - 太棒了!IO wait:等待網路。不消耗 OS 執行緒,因為它停放在非阻塞網路輪詢器上。sleep:我們都需要更多睡眠。select:在 select 上阻塞;等待 case 變為可用。select (no cases):專門在空 selectselect {}上阻塞。Caddy 在其 main 函數中使用一個來保持運行,因為關閉是從其他 goroutine 發起的。chan receive:在通道接收 (<-ch) 上阻塞。semacquire:等待獲取 semaphore(底層同步原語)。syscall:執行系統調用。消耗 OS 執行緒。
-
持續時間: goroutine 存在了多長時間。對於查找像 goroutine 洩漏這樣的錯誤很有用。例如,如果我們預期所有網路連線在幾分鐘後關閉,那麼當我們發現許多 netconn goroutine 存活了數小時時,這意味著什麼?
解釋 goroutine 傾印
在不查看程式碼的情況下,我們能從上面的 goroutine 中學到什麼?
它大約在一分鐘前建立,正在等待通過網路 socket 傳輸的資料,並且其 goroutine 編號非常大 (61961905)。
從第一個傾印 (debug=1) 中,我們知道它的調用堆疊執行頻率相對較高,並且大的 goroutine 編號與短持續時間相結合表明,已經有數千萬個相對短暫的 goroutine。它位於一個名為 pollWait 的函數中,其調用歷史包括從使用 TLS 的加密網路連線讀取 HTTP/2 幀。
因此,我們可以推斷出這個 goroutine 正在處理 HTTP/2 請求!它正在等待來自客戶端的資料。更重要的是,我們知道產生它的 goroutine 不是進程的第一批 goroutine 之一,因為它也具有很高的編號;在傾印中找到該 goroutine 會發現,它是在現有請求期間產生以處理新的 HTTP/2 stream。相比之下,編號較高的其他 goroutine 可能是由編號較低的 goroutine(例如 32)產生的,這表明來自 socket 的 Accept() 調用產生了全新的連線。
每個程式都不同,但在偵錯 Caddy 時,這些模式往往是成立的。
記憶體效能分析
記憶體(或 heap)效能分析追蹤 heap 分配,heap 分配是系統上記憶體的主要消耗者。分配也是效能問題的常見嫌疑物件,因為分配記憶體需要系統調用,這可能會很慢。
Heap 效能分析在幾乎所有方面都與 goroutine 效能分析相似,除了頂行的開頭。這是一個範例
0: 0 [1: 4096] @ 0xb1fc05 0xb1fc4d 0x48d8d1 0xb1fce6 0xb184c7 0xb1bc8e 0xb41653 0xb4105c 0xb4151d 0xb23b14 0x4719c1
# 0xb1fc04 bufio.NewWriterSize+0x24 bufio/bufio.go:599
# 0xb1fc4c golang.org/x/net/http2.glob..func8+0x6c golang.org/x/net@v0.17.0/http2/http2.go:263
# 0x48d8d0 sync.(*Pool).Get+0xb0 sync/pool.go:151
# 0xb1fce5 golang.org/x/net/http2.(*bufferedWriter).Write+0x45 golang.org/x/net@v0.17.0/http2/http2.go:276
# 0xb184c6 golang.org/x/net/http2.(*Framer).endWrite+0xc6 golang.org/x/net@v0.17.0/http2/frame.go:371
# 0xb1bc8d golang.org/x/net/http2.(*Framer).WriteHeaders+0x48d golang.org/x/net@v0.17.0/http2/frame.go:1131
# 0xb41652 golang.org/x/net/http2.(*writeResHeaders).writeHeaderBlock+0xd2 golang.org/x/net@v0.17.0/http2/write.go:239
# 0xb4105b golang.org/x/net/http2.splitHeaderBlock+0xbb golang.org/x/net@v0.17.0/http2/write.go:169
# 0xb4151c golang.org/x/net/http2.(*writeResHeaders).writeFrame+0x1dc golang.org/x/net@v0.17.0/http2/write.go:234
# 0xb23b13 golang.org/x/net/http2.(*serverConn).writeFrameAsync+0x73 golang.org/x/net@v0.17.0/http2/server.go:851
頂行格式如下
<live objects> <live memory> [<allocations>: <allocation memory>] @ <addresses...>
在上面的範例中,我們有一個由 bufio.NewWriterSize() 進行的單個分配,但目前沒有來自此調用堆疊的活動物件。
有趣的是,我們可以從調用堆疊中推斷出 http2 套件使用了池化的 4 KB 將 HTTP/2 幀寫入客戶端。如果您已優化熱路徑以重複使用分配,您通常會在 Go 記憶體效能分析中看到池化物件。這減少了新的分配,heap 效能分析可以幫助您了解池是否被正確使用!
CPU 效能分析
CPU 效能分析可幫助您了解 Go 程式在處理器上花費最多排程時間的位置。
但是,這些沒有純文字形式,因此在下一節中,我們將使用 go tool pprof 命令來幫助我們讀取它們。
要下載 CPU 效能分析,請向 /debug/pprof/profile?seconds=N 發出請求,其中 N 是您要收集效能分析的秒數。在 CPU 效能分析收集期間,程式效能可能會受到輕微影響。(其他效能分析幾乎沒有效能影響。)
完成後,它應該下載一個二進制檔案,恰如其分地命名為 profile。然後我們需要檢查它。
go tool pprof
我們將使用 Go 的內建效能分析分析器來讀取 CPU 效能分析作為範例,但您可以將其與任何類型的效能分析一起使用。
運行此命令(如果檔案路徑不同,請替換為實際檔案路徑 “profile”),這將打開一個互動式提示符
go tool pprof profile
File: caddy_master
Type: cpu
Time: Aug 29, 2022 at 8:47pm (MDT)
Duration: 30.02s, Total samples = 70.11s (233.55%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) 這是您可以探索的東西。輸入 help 會為您提供命令列表,o 將向您顯示當前選項。如果您輸入 help <command>,您可以獲得有關特定命令的資訊。
有很多命令,但一些常見的命令是
top:顯示哪個使用了最多的 CPU。您可以附加一個數字,例如top 20以查看更多內容,或使用正則表達式來“專注”於或忽略某些項目。web:在您的瀏覽器中打開調用圖。這是視覺化查看 CPU 使用率的好方法。svg:產生調用圖的 SVG 圖像。它與web相同,只是它不會打開您的瀏覽器,並且 SVG 會在本機保存。tree:調用堆疊的表格視圖。
讓我們從 top 開始。我們看到類似這樣的輸出
(pprof) top
Showing nodes accounting for 38.36s, 54.71% of 70.11s total
Dropped 785 nodes (cum <= 0.35s)
Showing top 10 nodes out of 196
flat flat% sum% cum cum%
10.97s 15.65% 15.65% 10.97s 15.65% runtime/internal/syscall.Syscall6
6.59s 9.40% 25.05% 36.65s 52.27% runtime.gcDrain
5.03s 7.17% 32.22% 5.34s 7.62% runtime.(*lfstack).pop (inline)
3.69s 5.26% 37.48% 11.02s 15.72% runtime.scanobject
2.42s 3.45% 40.94% 2.42s 3.45% runtime.(*lfstack).push
2.26s 3.22% 44.16% 2.30s 3.28% runtime.pageIndexOf (inline)
2.11s 3.01% 47.17% 2.56s 3.65% runtime.findObject
2.03s 2.90% 50.06% 2.03s 2.90% runtime.markBits.isMarked (inline)
1.69s 2.41% 52.47% 1.69s 2.41% runtime.memclrNoHeapPointers
1.57s 2.24% 54.71% 1.57s 2.24% runtime.epollwait
CPU 的前 10 個消耗者都在 Go 運行時中 - 特別是大量的垃圾回收(請記住,系統調用用於釋放和分配記憶體)。這是一個暗示,我們可以減少分配以提高效能,並且 heap 效能分析將是值得的。
好的,但是如果我們想查看我們自己程式碼的 CPU 使用率呢?我們可以像這樣忽略包含 “runtime” 的模式
(pprof) top -runtime
Active filters:
ignore=runtime
Showing nodes accounting for 0.92s, 1.31% of 70.11s total
Dropped 160 nodes (cum <= 0.35s)
Showing top 10 nodes out of 243
flat flat% sum% cum cum%
0.17s 0.24% 0.24% 0.28s 0.4% sync.(*Pool).getSlow
0.11s 0.16% 0.4% 0.11s 0.16% github.com/prometheus/client_golang/prometheus.(*histogram).observe (inline)
0.10s 0.14% 0.54% 0.23s 0.33% github.com/prometheus/client_golang/prometheus.(*MetricVec).hashLabels
0.10s 0.14% 0.68% 0.12s 0.17% net/textproto.CanonicalMIMEHeaderKey
0.10s 0.14% 0.83% 0.10s 0.14% sync.(*poolChain).popTail
0.08s 0.11% 0.94% 0.26s 0.37% github.com/prometheus/client_golang/prometheus.(*histogram).Observe
0.07s 0.1% 1.04% 0.07s 0.1% internal/poll.(*fdMutex).rwlock
0.07s 0.1% 1.14% 0.10s 0.14% path/filepath.Clean
0.06s 0.086% 1.23% 0.06s 0.086% context.value
0.06s 0.086% 1.31% 0.06s 0.086% go.uber.org/zap/buffer.(*Buffer).AppendByte
好吧,很明顯 Prometheus 指標是另一個主要消耗者,但您會注意到,累積起來,它們的數量級遠小於上面的 GC。鮮明的差異表明我們應該專注於減少 GC。
讓我們使用 q 退出此效能分析,並在 heap 效能分析上使用相同的命令
(pprof) top
Showing nodes accounting for 22259.07kB, 81.30% of 27380.04kB total
Showing top 10 nodes out of 102
flat flat% sum% cum cum%
12300kB 44.92% 44.92% 12300kB 44.92% runtime.allocm
2570.01kB 9.39% 54.31% 2570.01kB 9.39% bufio.NewReaderSize
2048.81kB 7.48% 61.79% 2048.81kB 7.48% runtime.malg
1542.01kB 5.63% 67.42% 1542.01kB 5.63% bufio.NewWriterSize
...
賓果。幾乎一半的記憶體嚴格地分配給我們使用 bufio 套件的讀取和寫入緩衝區。因此,我們可以推斷出,優化我們的程式碼以減少緩衝將非常有益。(Caddy 中的相關修補程式 正是這樣做的)。
視覺化
如果我們改為運行 svg 或 web 命令,我們將獲得效能分析的可視化
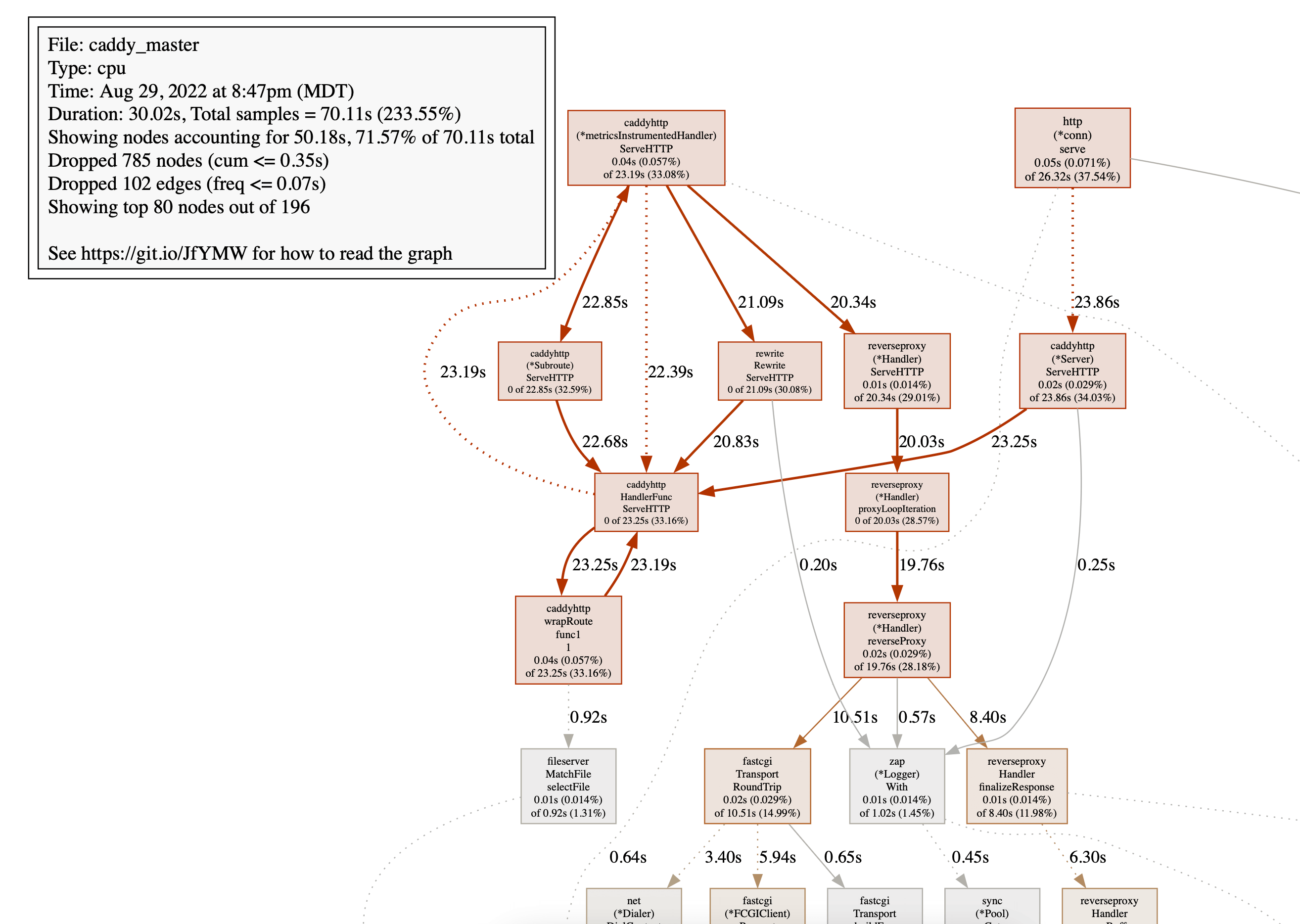
這是 CPU 效能分析,但類似的圖形可用於其他效能分析類型。
要了解如何讀取這些圖形,請閱讀 pprof 文件。
差異化效能分析
在您進行程式碼更改後,您可以使用差異分析 (“diff”) 來比較之前和之後的情況。這是 heap 的差異
go tool pprof -diff_base=before.prof after.prof
File: caddy
Type: inuse_space
Time: Aug 29, 2022 at 1:21am (MDT)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for -26.97MB, 49.32% of 54.68MB total
Dropped 10 nodes (cum <= 0.27MB)
Showing top 10 nodes out of 137
flat flat% sum% cum cum%
-27.04MB 49.45% 49.45% -27.04MB 49.45% bufio.NewWriterSize
-2MB 3.66% 53.11% -2MB 3.66% runtime.allocm
1.06MB 1.93% 51.18% 1.06MB 1.93% github.com/yuin/goldmark/util.init
1.03MB 1.89% 49.29% 1.03MB 1.89% github.com/caddyserver/caddy/v2/modules/caddyhttp/reverseproxy.glob..func2
1MB 1.84% 47.46% 1MB 1.84% bufio.NewReaderSize
-1MB 1.83% 49.29% -1MB 1.83% runtime.malg
1MB 1.83% 47.46% 1MB 1.83% github.com/caddyserver/caddy/v2/modules/caddyhttp/reverseproxy.cloneRequest
-1MB 1.83% 49.29% -1MB 1.83% net/http.(*Server).newConn
-0.55MB 1.00% 50.29% -0.55MB 1.00% html.populateMaps
0.53MB 0.97% 49.32% 0.53MB 0.97% github.com/alecthomas/chroma.TypeRemappingLexer如您所見,我們將記憶體分配減少了大約一半!
差異也可以視覺化
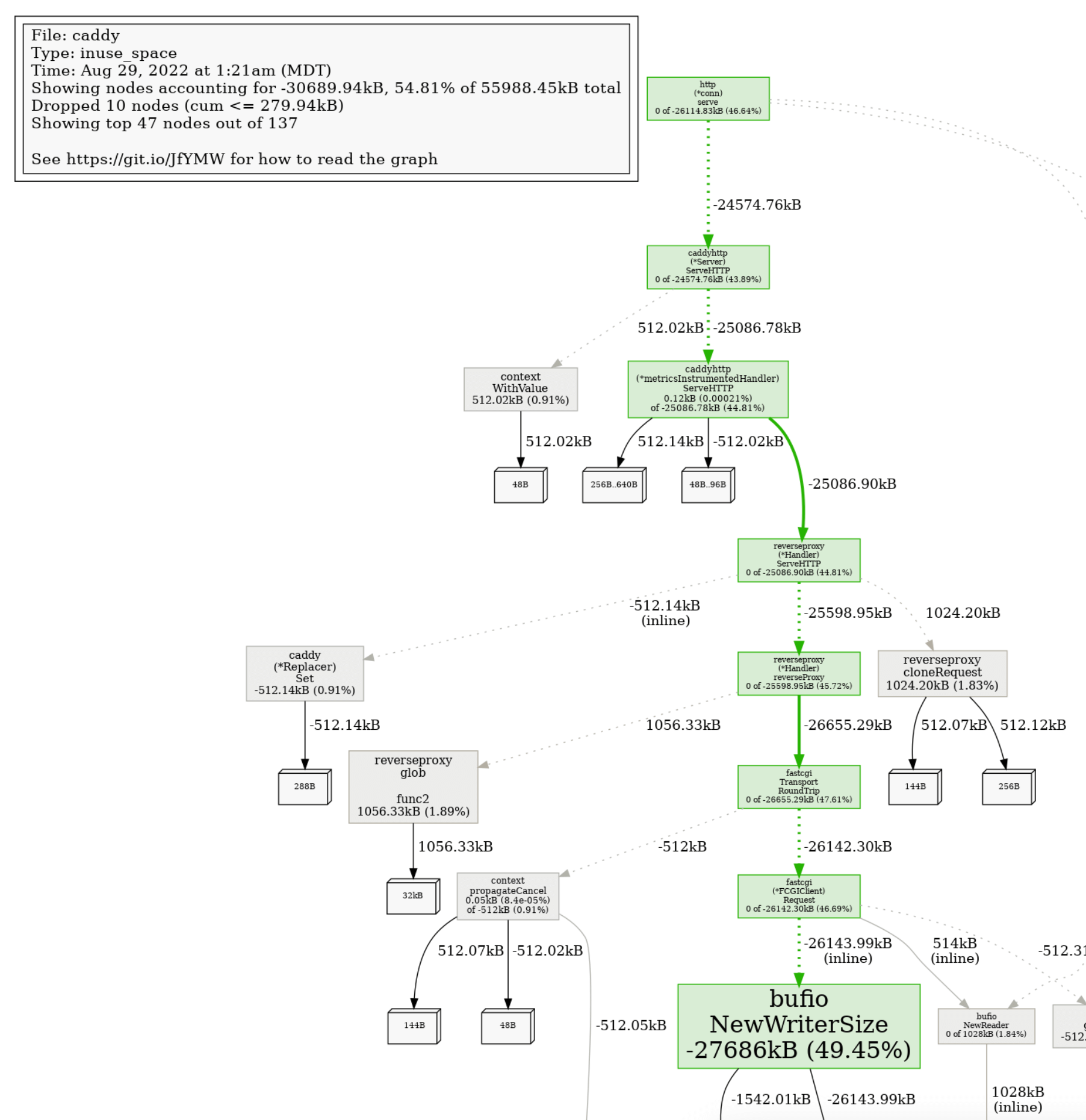
這使得更改如何影響程式某些部分的效能變得非常明顯。
進一步閱讀
程式效能分析有很多需要掌握的知識,而我們僅僅觸及了表面。
為了真正將 “pro” 融入 “profiling” 中,請考慮以下資源